As I was saying, actually parsing an XML document is very simple: one line of code. Where you go from there is up to you.
Example 9.8. Loading an XML document (for real this time)
>>> from xml.dom import minidom 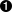 >>> xmldoc = minidom.parse('~/diveintopython/common/py/kgp/binary.xml')
>>> xmldoc = minidom.parse('~/diveintopython/common/py/kgp/binary.xml') 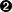 >>> xmldoc
>>> xmldoc  <xml.dom.minidom.Document instance at 010BE87C>
>>> print xmldoc.toxml()
<xml.dom.minidom.Document instance at 010BE87C>
>>> print xmldoc.toxml()  <?xml version="1.0" ?>
<grammar>
<ref id="bit">
<p>0</p>
<p>1</p>
</ref>
<ref id="byte">
<p><xref id="bit"/><xref id="bit"/><xref id="bit"/><xref id="bit"/>\
<xref id="bit"/><xref id="bit"/><xref id="bit"/><xref id="bit"/></p>
</ref>
</grammar>
<?xml version="1.0" ?>
<grammar>
<ref id="bit">
<p>0</p>
<p>1</p>
</ref>
<ref id="byte">
<p><xref id="bit"/><xref id="bit"/><xref id="bit"/><xref id="bit"/>\
<xref id="bit"/><xref id="bit"/><xref id="bit"/><xref id="bit"/></p>
</ref>
</grammar>
|
|
As you saw in the previous section, this imports the minidom module from the xml.dom package.
|
|
|
Here is the one line of code that does all the work: minidom.parse takes one argument and returns a parsed representation of the XML document. The argument can be many things; in this case, it's simply a filename of an XML document on my local disk. (To follow along, you'll need to change the path to point to your downloaded examples directory.)
But you can also pass a file object, or even a file-like object. You'll take advantage of this flexibility later in this chapter.
|
|
|
The object returned from minidom.parse is a Document object, a descendant of the Node class. This Document object is the root level of a complex tree-like structure of interlocking Python objects that completely represent the XML document you passed to minidom.parse.
|
|
|
toxml is a method of the Node class (and is therefore available on the Document object you got from minidom.parse). toxml prints out the XML that this Node represents. For the Document node, this prints out the entire XML document.
|
Now that you have an XML document in memory, you can start traversing through it.
Example 9.9. Getting child nodes
>>> xmldoc.childNodes
[<DOM Element: grammar at 17538908>]
>>> xmldoc.childNodes[0]
<DOM Element: grammar at 17538908>
>>> xmldoc.firstChild
<DOM Element: grammar at 17538908>
|
|
Every Node has a childNodes attribute, which is a list of the Node objects. A Document always has only one child node, the root element of the XML document (in this case, the grammar element).
|
|
|
To get the first (and in this case, the only) child node, just use regular list syntax. Remember, there is nothing special
going on here; this is just a regular Python list of regular Python objects.
|
|
|
Since getting the first child node of a node is a useful and common activity, the Node class has a firstChild attribute, which is synonymous with childNodes[0]. (There is also a lastChild attribute, which is synonymous with childNodes[-1].)
|
Example 9.10. toxml works on any node
>>> grammarNode = xmldoc.firstChild
>>> print grammarNode.toxml()
<grammar>
<ref id="bit">
<p>0</p>
<p>1</p>
</ref>
<ref id="byte">
<p><xref id="bit"/><xref id="bit"/><xref id="bit"/><xref id="bit"/>\
<xref id="bit"/><xref id="bit"/><xref id="bit"/><xref id="bit"/></p>
</ref>
</grammar>
|
|
Since the toxml method is defined in the Node class, it is available on any XML node, not just the Document element.
|
Example 9.11. Child nodes can be text
>>> grammarNode.childNodes
[<DOM Text node "\n">, <DOM Element: ref at 17533332>, \
<DOM Text node "\n">, <DOM Element: ref at 17549660>, <DOM Text node "\n">]
>>> print grammarNode.firstChild.toxml()
>>> print grammarNode.childNodes[1].toxml()
<ref id="bit">
<p>0</p>
<p>1</p>
</ref>
>>> print grammarNode.childNodes[3].toxml()
<ref id="byte">
<p><xref id="bit"/><xref id="bit"/><xref id="bit"/><xref id="bit"/>\
<xref id="bit"/><xref id="bit"/><xref id="bit"/><xref id="bit"/></p>
</ref>
>>> print grammarNode.lastChild.toxml() 
|
|
Looking at the XML in binary.xml, you might think that the grammar has only two child nodes, the two ref elements. But you're missing something: the carriage returns! After the '<grammar>' and before the first '<ref>' is a carriage return, and this text counts as a child node of the grammar element. Similarly, there is a carriage return after each '</ref>'; these also count as child nodes. So grammar.childNodes is actually a list of 5 objects: 3 Text objects and 2 Element objects.
|
|
|
The first child is a Text object representing the carriage return after the '<grammar>' tag and before the first '<ref>' tag.
|
|
|
The second child is an Element object representing the first ref element.
|
|
|
The fourth child is an Element object representing the second ref element.
|
|
|
The last child is a Text object representing the carriage return after the '</ref>' end tag and before the '</grammar>' end tag.
|
Example 9.12. Drilling down all the way to text
>>> grammarNode
<DOM Element: grammar at 19167148>
>>> refNode = grammarNode.childNodes[1]
>>> refNode
<DOM Element: ref at 17987740>
>>> refNode.childNodes
[<DOM Text node "\n">, <DOM Text node " ">, <DOM Element: p at 19315844>, \
<DOM Text node "\n">, <DOM Text node " ">, \
<DOM Element: p at 19462036>, <DOM Text node "\n">]
>>> pNode = refNode.childNodes[2]
>>> pNode
<DOM Element: p at 19315844>
>>> print pNode.toxml()
<p>0</p>
>>> pNode.firstChild
<DOM Text node "0">
>>> pNode.firstChild.data
u'0'
|
|
As you saw in the previous example, the first ref element is grammarNode.childNodes[1], since childNodes[0] is a Text node for the carriage return.
|
|
|
The ref element has its own set of child nodes, one for the carriage return, a separate one for the spaces, one for the p element, and so forth.
|
|
|
You can even use the toxml method here, deeply nested within the document.
|
|
|
The p element has only one child node (you can't tell that from this example, but look at pNode.childNodes if you don't believe me), and it is a Text node for the single character '0'.
|
|
|
The .data attribute of a Text node gives you the actual string that the text node represents. But what is that 'u' in front of the string? The answer to that deserves its own section.
|